CUDA编程模型

https://developer.nvidia.com/blog/cuda-refresher-cuda-programming-model/
- 一组线程组成一个CUDA block
- 一组CUDA block组成一个CUDA grid
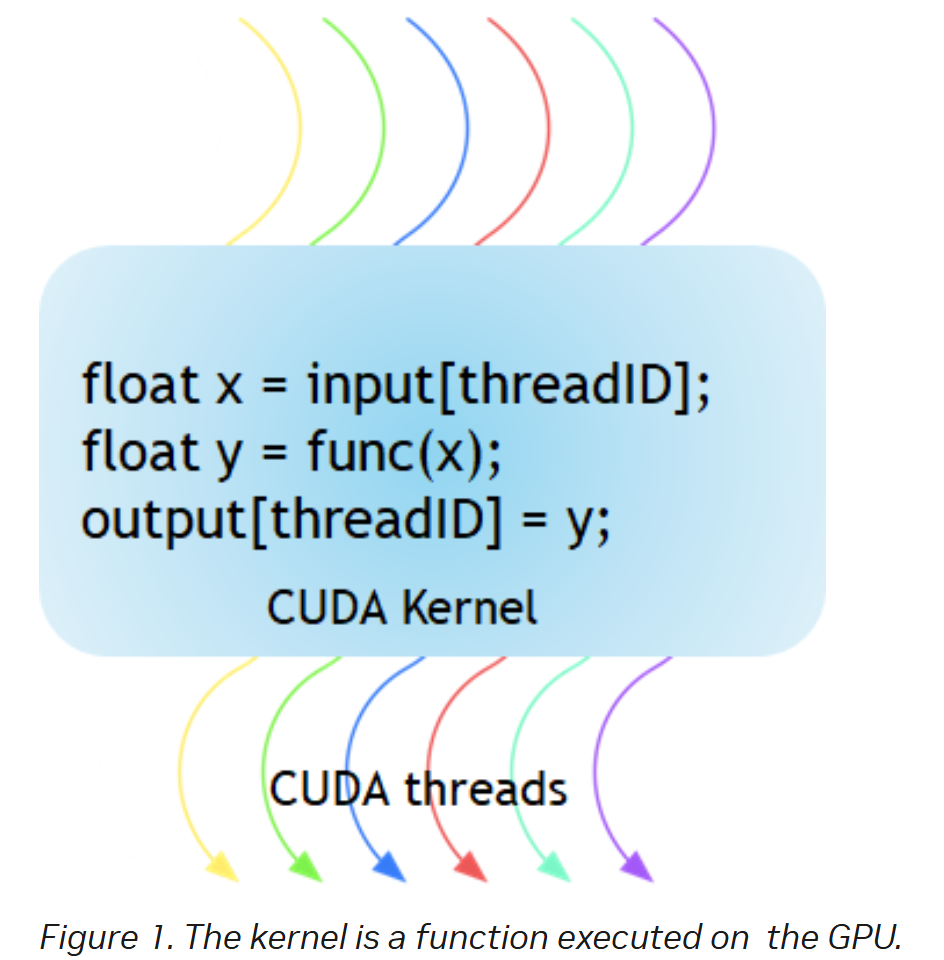
- 每个CUDA block只能在一个CUDA SM上执行,不可以跨SM
- 每个SM可以跑多个并发的CUDA block
- 每个线程可以用一个三维的索引来标识自己的位置,比如
threadIdx.x,threadIdx.y,threadIdx.z
一些概念辨析
- 一直对SM, grid, thread block, warp, CUDA core几个概念有点晕,今天梳理了一下
- 感觉单独解释有点乱,打算给出一些正确的陈述句,有点像判断题的格式(笑
- warp是GPU执行的最小单位
- GPU在执行指令的时候,它会在一个时钟周期里面执行同一条指令的32个线程,也就是一个warp,一个warp就包含32个线程
- 这个可以看GPU的结构来理解,warp是从GPU硬件的角度来说的,他就一次性执行一个warp
- 同在一个warp的线程,以不同的数据执行相同的指令,这就是SIMT
- thread block是分配资源的最小单位
- 一个thread block内的资源是共享的,比如共享内存
- CUDA core就有点像CPU里面的ALU,同一个时钟周期内只执行一条指令
- grid是所有线程块的集合
- 是整个计算任务的所有线程块集合
- 一个CUDA kernel启动,实际上启动了一整个grid
- 一个线程块一定只能在一个SM里面执行,不能跨SM,要不然还怎么用共享内存
- 如果一个线程块里面的线程数量少于32个,那仍然会分配一个32线程的warp,只不过剩下的线程就浪费掉了
- 程序员在开发时,通过设定block的属性,告诉GPU硬件,我有多少个线程,线程怎么组织。而具体怎么调度由sm的warps scheduler负责,block一旦被分配好SM,该block就会一直驻留在该SM中,直到执行结束。(参考:https://blog.csdn.net/junparadox/article/details/50540602)
- 我之前一直搞不懂,都有了warp了还要block这个概念干啥,其实block的概念更多的是在实际应用中起作用,比如我们算两个矩阵的加法,那么就很自然的会希望每个线程都去处理一个矩阵元素,那就会希望将负责的线程组织成一个二维的线程块,正好一一映射过去。那这一个block里面的线程自然是执行相同的代码,这一个block都会进入一个SM,然后可以通过共享内存通信。