NCCL代码阅读-02

NCCL中重要的数据结构(持续更新)
struct ncclComm
实际使用的时候是
1 | typedef struct ncclComm* ncclComm_t; |
- 在src\nccl.h.in
- 通信上下文
- 比如两张GPU通信,每个GPU上都有一个comm,每个GPU都有一个rank,他们俩共享一个uniqueId,这个uniqueId是由root GPU生成的,然后广播给其他GPU,这样其他GPU就知道了这个通信上下文的uniqueId
struct ncclInfo
- 这个结构一直用到最后….功能很多,后面慢慢加
struct ncclKernelPlanner
BytePack
这个 BytePack<16> 是一个 联合体 (union),主要用于在内存中以对齐和打包的方式操作数据。下面是对这个联合体的详细解析:
1. 用途
BytePack<16> 是一个能够表示 16 字节(128 位)数据块 的数据结构,提供了多种访问方式,适用于高性能代码中高效的内存操作和数据对齐。
2. 结构解析
alignas(16)
- 含义:该联合体的起始地址在内存中会被对齐到 16 字节边界。
- 目的:确保硬件在访问该数据时,可以利用内存对齐的特性实现更高效的读写操作(特别是在 SIMD 或 GPU 中很重要)。
成员列表
BytePack<8> half[2]- 含义:将 16 字节的数据分为两个 8 字节的
BytePack<8>。 - 用途:可以将 16 字节的数据一分为二进行单独处理。
- 含义:将 16 字节的数据分为两个 8 字节的
uint8_t u8[16]- 含义:按字节访问 16 字节的数据。
- 用途:用于逐字节操作,例如处理非对齐的原始数据流。
uint16_t u16[8]- 含义:按 2 字节(16 位)为单位访问数据,总共有 8 个 16 位数据。
- 用途:适合操作 16 位的数据类型,如半精度浮点数(fp16)。
uint32_t u32[4]- 含义:按 4 字节(32 位)为单位访问数据,总共有 4 个 32 位数据。
- 用途:适合操作 32 位数据类型,例如单精度浮点数(fp32)或整数。
uint64_t u64[2]- 含义:按 8 字节(64 位)为单位访问数据,总共有 2 个 64 位数据。
- 用途:适合操作 64 位的数据类型,例如双精度浮点数(fp64)。
ulong2 ul2, native- 含义:将 16 字节的数据看作两个 64 位的值组成的矢量(
ulong2是 CUDA/NVIDIA 数据类型,表示 2 个 64 位无符号整数的结构体)。 - 用途:适合矢量化操作,例如在 GPU 上使用
vectorized数据访问。
- 含义:将 16 字节的数据看作两个 64 位的值组成的矢量(
3. 为何使用联合体
联合体的特点:
联合体中的所有成员共享同一段内存空间(16 字节),但提供了多种不同的访问方式。目的:
- 通过共享内存节省空间。
- 提供灵活的内存操作接口:
- 可以以 8 位、16 位、32 位、64 位或矢量的方式操作数据。
- 对齐至 16 字节边界,优化硬件访问性能。
4. 典型用途
高性能数据传输
在 NCCL 或类似 GPU 通信库中,常见的需求是以大块数据为单位(如 16 字节或 128 位)进行高效的数据传输,同时能够支持多种数据类型。
- 例如:
- 将 16 字节数据传输到 GPU 的全局内存时:
u64[2]可以以两个 64 位为单位高效操作。
- 处理每个字节的内容时:
- 使用
u8[16]逐字节访问。
- 使用
- 将 16 字节数据传输到 GPU 的全局内存时:
SIMD 和 GPU 内存访问
- 在 SIMD(单指令多数据)或 GPU 中,硬件通常要求对齐访问。例如,某些 GPU 指令只能对齐到 16 字节。
- 使用
BytePack<16>确保数据对齐,并提供多种访问方式,适合不同场景下的优化。
5. 示例
假设我们有一个 BytePack<16> 对象 pack:
1 | BytePack<16> pack; |
6. 总结
BytePack<16>的功能:- 提供灵活的接口操作 16 字节的数据块。
- 确保对齐性能,适配高效内存访问。
典型场景:
- 高性能计算中的数据传输、规约。
- GPU 上的矢量化操作。
- SIMD 或其他对齐要求的硬件加速任务。
NCCL代码中常用的函数和宏定义
NCCLCHECK
NCCLCHECK 是一个宏,用于简化 NCCL 函数调用后的错误检查。在 NCCL 和许多 C/C++ 编程环境中,错误处理通常是一个关键部分,而通过宏封装可以使代码更加简洁和易于维护。
NCCLCHECK 的典型定义
在 NCCL 的代码中,NCCLCHECK 通常是定义为类似下面的宏:
1 |
功能
- 执行函数调用并捕获返回值
call是需要执行的 NCCL 函数,比如ncclInit()或PtrCheck(out, "GetUniqueId", "out")。这些函数通常返回一个类型为ncclResult_t的结果,用于指示是否成功。
使用示例
在代码中,NCCLCHECK 的作用是捕获和处理 NCCL 函数的错误。例如:
1 | NCCLCHECK(ncclInit()); |
等价于:
1 | { |
cudaSetDevice
1 | cudaError_t cudaSetDevice(int device); |
- 其实这并不是一个NCCL的函数,而是一个CUDA runtime的API
- 用于设置当前线程的CUDA设备(GPU)
- 就是说,我现在如果调用了cudaSetDevice(1),那么接下来的CUDA函数调用都会在GPU 1上执行(我在操作1号设备),直到我再次对另一个设备调用cudaSetDevice
cudaMalloc
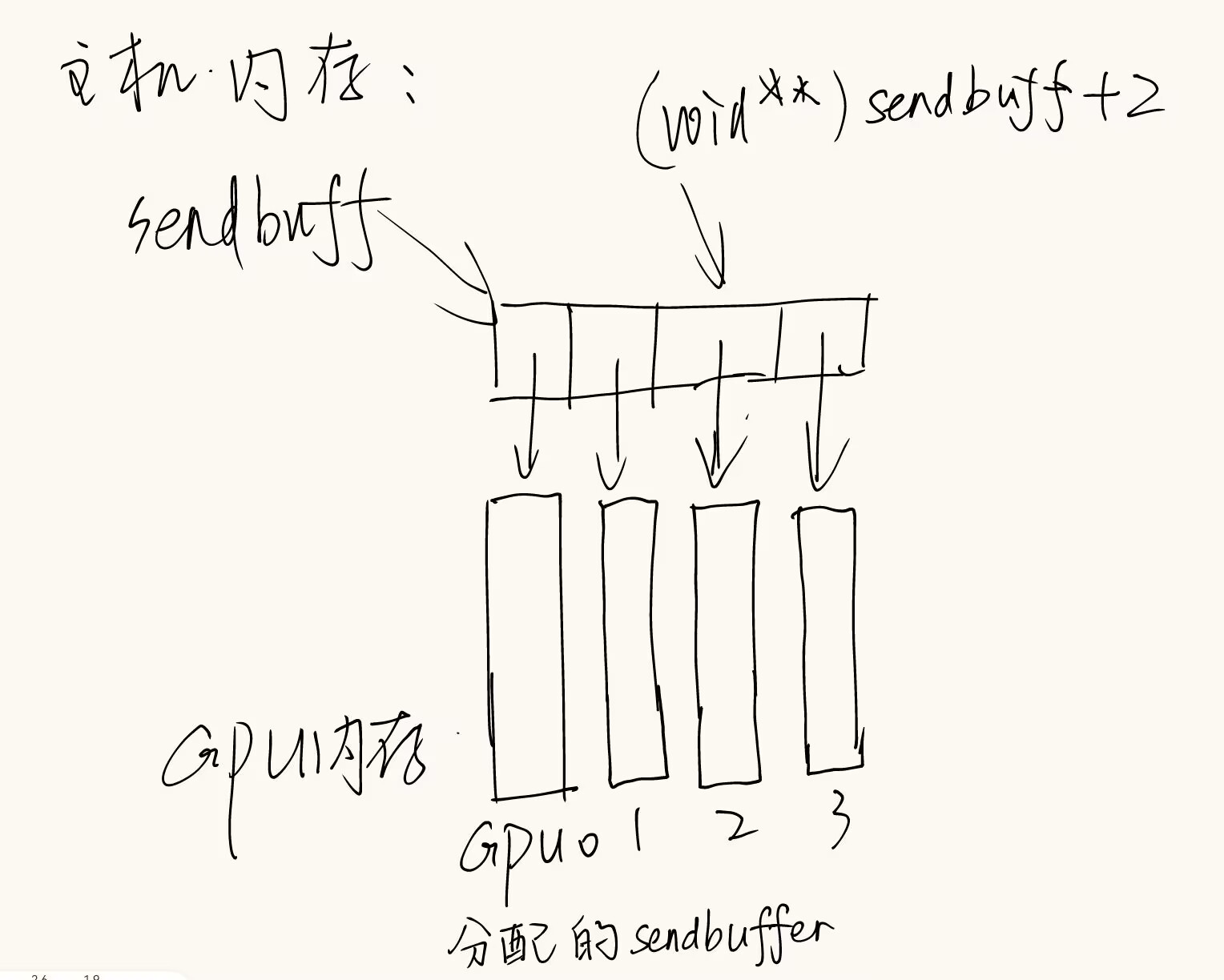
1 | cudaError_t cudaMalloc(void** devPtr, size_t size); |
- 为设备分配内存,这个设备就是之前用cudaSetDevice设置的设备
- devPtr是一个指向指针的指针,指向的指针存的是分配的内存的地址
- 举例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14// allocating and initializing device buffers
float **sendbuff = (float **)malloc(nDev * sizeof(float *));
float **recvbuff = (float **)malloc(nDev * sizeof(float *));
cudaStream_t *s = (cudaStream_t *)malloc(sizeof(cudaStream_t) * nDev);
for (int i = 0; i < nDev; ++i)
{
CUDACHECK(cudaSetDevice(i));
CUDACHECK(cudaMalloc((void **)sendbuff + i, size * sizeof(float)));
CUDACHECK(cudaMalloc((void **)recvbuff + i, size * sizeof(float)));
CUDACHECK(cudaMemset(sendbuff[i], 1, size * sizeof(float)));
CUDACHECK(cudaMemset(recvbuff[i], 0, size * sizeof(float)));
CUDACHECK(cudaStreamCreate(s + i));
}
group API
1. Group Calls (组调用) 的概念
ncclGroupStart() 和 ncclGroupEnd() 是 NCCL 提供的两个函数,用于将多个 NCCL 操作合并成一个操作进行执行。这些操作会在同一个 NCCL group 内顺序执行,从而减少了多次启动 NCCL 操作时的开销。通过使用组调用,NCCL 可以更高效地管理并发操作,尤其是在涉及多个 GPU 或多线程的场景下。
**
ncclGroupStart()**:启动一个 NCCL 操作组。所有在这个调用后到ncclGroupEnd()之前的 NCCL 操作都会被视作同一个组的一部分。**
ncclGroupEnd()**:结束 NCCL 操作组,并提交所有在ncclGroupStart()和ncclGroupEnd()之间的操作。调用这个函数后,NCCL 会将所有操作打包在一起,并尽可能高效地执行。
下面如果不使用组调用(ncclGroupStart() 和 ncclGroupEnd()),会发生什么,执行的具体过程是怎样的。
2. 组调用作用之一:管理多个 GPU 的通信操作
示例:多个设备上的 ncclAllReduce
假设我们有多个 GPU(例如 4 个),并希望在每个 GPU 上执行相同的 NCCL 操作(例如 ncclAllReduce)。不使用 ncclGroupStart() 和 ncclGroupEnd() 时,你可能会在每个 GPU 上执行一次 ncclAllReduce 操作,每次都可能会等待前一个操作完成,这样会增加执行时间和延迟。
使用 ncclGroupStart() 和 ncclGroupEnd()
1 | ncclGroupStart(); // 开始一个 NCCL 操作组 |
- 在这里,
ncclGroupStart()和ncclGroupEnd()包围了所有的ncclAllReduce调用,所有操作会被视为同一个组的一部分。 - 执行顺序:NCCL 会在后台调度这些操作并行执行。每个 GPU 上的操作并不会阻塞其他操作的执行。
- 性能:所有 GPU 上的
ncclAllReduce操作可以并行执行,减少了同步和启动开销。
不使用 ncclGroupStart() 和 ncclGroupEnd()
1 | for (int i = 0; i < nLocalDevs; i++) { |
执行顺序:如果不使用组调用,NCCL 会逐个执行这些
ncclAllReduce操作,等待每个操作完成后再执行下一个操作。- 比如,假设有 4 个 GPU,
ncclAllReduce操作会依次执行,每次执行时都会等待前一个操作完成,然后才会开始下一个操作。这种顺序执行会导致明显的延迟。
- 比如,假设有 4 个 GPU,
死锁风险:如果在每个操作中都需要同步,且这些操作依赖于其他线程/进程的结果,可能会导致死锁或不必要的阻塞。例如,
ncclAllReduce在每个设备上执行时,可能需要等待所有设备的操作完成。如果按代码顺序挨个执行(其实就是阻塞),那后一个操作必须等前一个做完才能进行,但实际上,他俩应该同时执行。
3. 组调用作用之二:在创建通信器时使用 Group Calls
示例:在一个线程中管理多个 GPU
假设你有一个线程需要初始化多个 GPU 上的 NCCL 通信器。初始化操作(如 ncclCommInitRank)通常是一个阻塞操作,如果不使用 ncclGroupStart() 和 ncclGroupEnd(),这些初始化操作会依次执行,每次操作都必须等待前一个操作完成,这可能会浪费时间。
使用 ncclGroupStart() 和 ncclGroupEnd()
1 | ncclGroupStart(); // 开始一个 NCCL 操作组 |
- 执行顺序:
ncclCommInitRank调用会并行地在每个 GPU 上执行。 - 性能:因为通信器的初始化操作是通过组调用来管理的,NCCL 可以在后台并行处理所有设备的初始化操作,而不是一个接一个地执行。这减少了初始化的时间。
不使用 ncclGroupStart() 和 ncclGroupEnd()
1 | for (int i = 0; i < nLocalDevs; i++) { |
- 执行顺序:
ncclCommInitRank会按顺序执行,等待每个设备的初始化完成后再继续执行下一个设备的初始化。 - 性能:没有组调用,通信器初始化会串行执行,导致设备初始化时间更长。如果有多个 GPU,这会浪费很多时间在设备间的同步和等待上。
3. 组调用作用之三:聚合通信操作
示例:多个集体操作(ncclBroadcast 和 ncclAllReduce)聚合
假设你想在多个 GPU 上执行多个不同的 NCCL 集体操作(例如,一个 ncclBroadcast 和两个 ncclAllReduce)。如果不使用组调用,NCCL 会为每个操作单独启动一次通信。
使用 ncclGroupStart() 和 ncclGroupEnd()
1 | ncclGroupStart(); // 开始 NCCL 操作组 |
- 执行顺序:所有的集体操作(
ncclBroadcast和ncclAllReduce)会被合并到一个组中执行。NCCL 会将这些操作作为一个批次提交,减少了每个操作单独启动时的开销。 - 性能:通过将多个操作合并成一个组,NCCL 只需要发起一次通信并等待完成,从而减少了启动和同步的延迟。
不使用 ncclGroupStart() 和 ncclGroupEnd()
1 | ncclBroadcast(sendbuff1, recvbuff1, count1, datatype, root, comm, stream); |
- 执行顺序:每个
ncclBroadcast和ncclAllReduce操作都会单独执行,NCCL 会依次启动每个操作并等待前一个操作完成。这样,可能会在每个操作之间产生额外的延迟,尤其是在启动多个 NCCL 操作时。 - 性能:每个操作都会带来额外的启动开销,导致总体性能下降。
4. 额外补充:阻塞组和非阻塞组
阻塞组(Blocking Group)
阻塞组意味着当调用 ncclGroupEnd() 时,NCCL 会等待所有在 ncclGroupStart() 和 ncclGroupEnd() 之间的 NCCL 操作完全完成(包括启动、执行和同步)。在这种模式下,ncclGroupEnd() 会在所有操作完成后返回,意味着直到所有操作完成,你才能继续执行后续的代码。
阻塞组的特点:
- 所有组中的 NCCL 操作会按顺序依次发起并等待完成。
ncclGroupEnd()会阻塞直到所有 NCCL 操作都完成。- 阻塞组适用于你希望在继续执行其他任务之前等待所有 NCCL 操作完成的场景。
示例:
1 | ncclGroupStart(); // 开始一个 NCCL 操作组 |
在这个例子中,ncclGroupEnd() 会阻塞,直到所有的 ncclAllReduce 操作完成。这样可以确保在 ncclGroupEnd() 返回之前,所有的 NCCL 操作都已经被提交和执行。
2. 非阻塞组(Non-blocking Group)
非阻塞组指的是当你调用 ncclGroupEnd() 时,NCCL 并不会阻塞直到所有操作完成。相反,ncclGroupEnd() 会尽快返回,并表示操作组已被提交,但后台的 NCCL 操作可能仍在执行中。这种模式允许你执行其他任务,同时在后台继续完成 NCCL 操作。
- 非阻塞组的核心是当
ncclGroupEnd()返回时,NCCL 操作可能仍在后台执行。这时你可以检查操作是否完成(通过查看返回状态或使用异步错误检查),而不是等待它们同步完成。 - 非阻塞组适用于你希望进行并行操作或不希望阻塞主线程的场景,例如,你希望继续执行其他计算或通信操作,而不是等待每个 NCCL 操作完成。
非阻塞组的特点:
ncclGroupEnd()会尽快返回,不会等待所有操作完成。- 当组中的操作还在后台执行时,
ncclGroupEnd()会返回ncclInProgress,表示操作仍在进行。 - 你可以通过调用
ncclCommGetAsyncError()来检查操作的状态,以便确认 NCCL 操作是否完成。 - 如果使用非阻塞组,通常需要在后续代码中进行同步(如调用
cudaStreamSynchronize())来确保所有操作完成。
示例:
1 | ncclGroupStart(); // 开始一个 NCCL 操作组 |
在这个例子中,ncclGroupEnd() 会尽快返回,并可能返回 ncclInProgress,表示 NCCL 操作仍在后台进行。你可以通过调用 ncclCommGetAsyncError() 来轮询每个操作的状态,并在操作完成时继续执行后续代码。