DeepEP-decode阶段microbatch重叠分析

前言
- 简单分析一下deepep的LL kernel,即用于推理的decode阶段的通信kernel。代码就不在这看了,主要是分析一下其对于双microbatch的支持。
- 之前一直对双buffer的使用有些误区,始终觉得会把干净数据弄脏,现在仔细想起来并不会这样。
图片解释
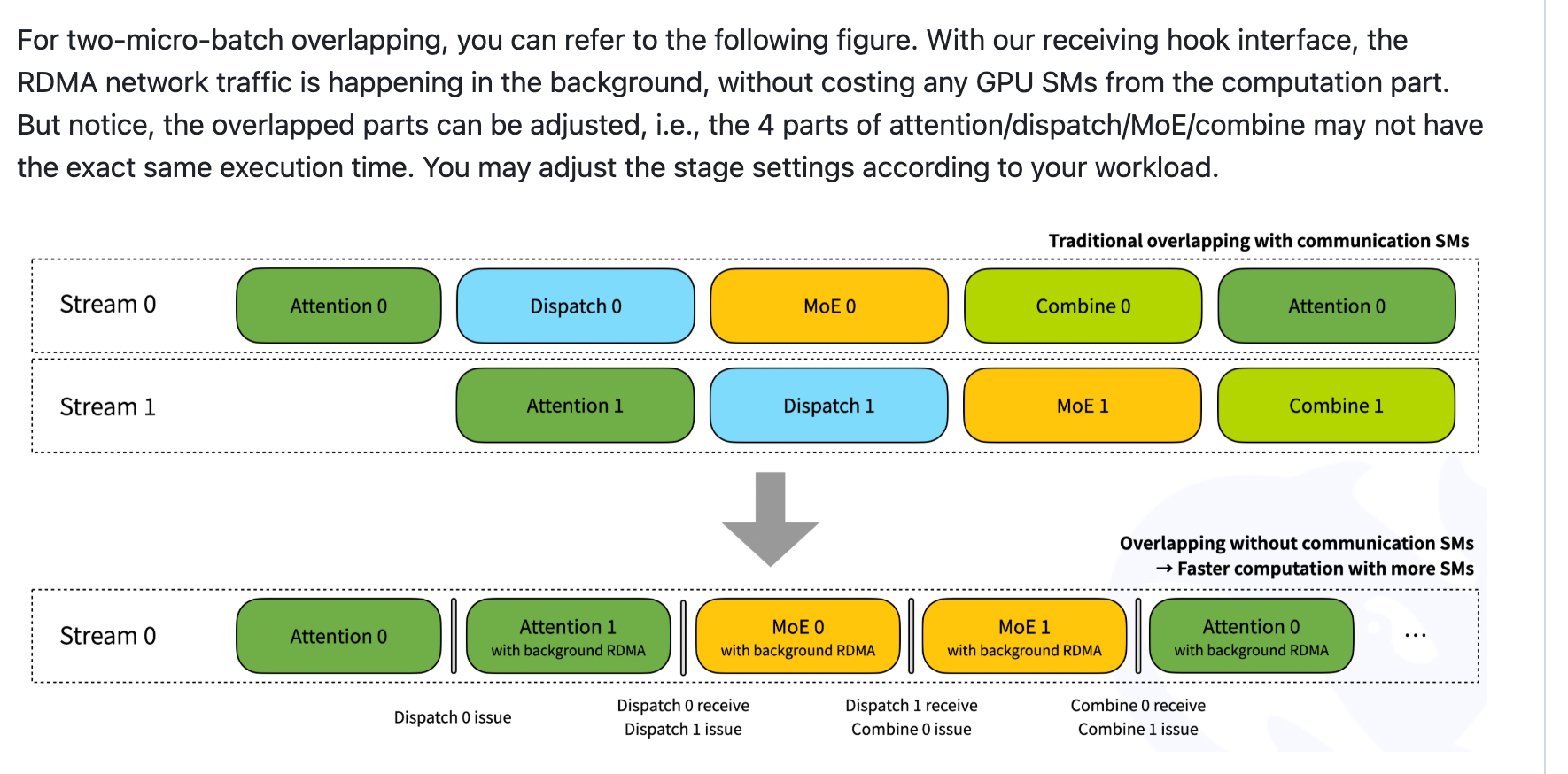
- 我们看上面一张图片,要用两个stream,分别负责一个microbatch,主要原因是通信时间是显式漏在外面的
- 而下面这张图里,两个microbatch用的是同一个stream,通信因为使用了RDMA,所以只是作为背景进行的,所以可以被计算时间掩盖掉。
- deepep里面使用了一个双buffer的设计,也就是一个stream开了两套buffer,每一套buffer里面都有一个send buffer和一个recv buffer,所以一共是两个send buffer两个recv buffer。
分阶段解释
- Phase 1:dispatch 0 send(issue)使用了send buffer A
- Phase 2:进入dispatch 0 recv和dispatch 1 issue(buffer B)。这里dispatch 0 recv接收的是别的GPU发来的dispatch 0,并不一定保证自己发出的dispatch send 0已经被别人接收。同时,由于一个stream上只能同时出现一个通信kernel,所以是先dispatch 0 recv再dispatch 1 issue的。
- Phase 3:dispatch 1 recv,然后combine 0 issue。这里combine 0使用的是dispatch 0 issue的buffer A,但是不会有问题(有问题指,因为不确定别人是否已经收到我发送的dispatch 0,所以如果直接写新数据可能会出问题),因为前面已经发生了dispatch 1 recv,而dispatch 1的recv说明别的rank一定已经全部进行了dispatch 1的send,又因为stream的顺序,说明别的rank也都全部进行完了Phase2的dispatch 0 recv,所以没问题